The landscape of local artificial intelligence has expanded beyond text. With the release of highly efficient vision-language models (VLMs), developers can now run multimodal applications locally on consumer hardware. Models like Qwen 2.5 VL, Llama 3.2 Vision, and Pixtral 12B can analyze images, perform document OCR, and interpret charts entirely offline.
However, multimodal models present unique hardware challenges. Processing visual tokens alongside textual data increases computational overhead and memory usage. This guide analyzes VLM architectures and provides optimization strategies for local CPU and GPU environments.
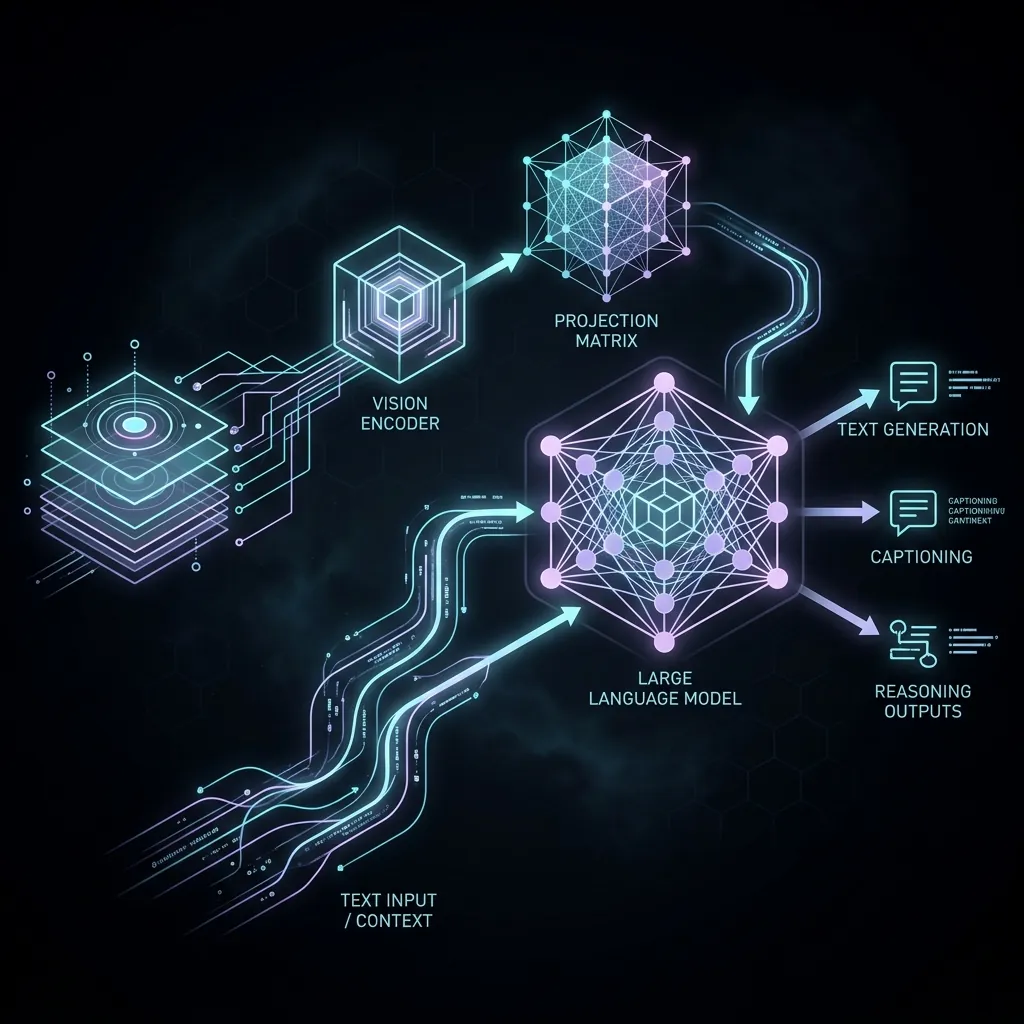
The Architecture of local Multimodal Models
To optimize vision-language models, we must first understand how they process text and images. A standard local VLM contains three primary components:
- The Vision Encoder: A Vision Transformer (ViT) that processes raw pixels. It partitions the input image into patches, processes them, and outputs high-dimensional visual feature vectors.
- The Multimodal Projector: A cross-attention layer or MLP (Multi-Layer Perceptron) that maps visual feature vectors into the same embedding space utilized by the text model.
- The Text LLM Backbone: The core decoder-only transformer (e.g., Llama or Qwen) that processes the unified sequence of text and visual tokens to generate responses.
When an image is loaded, it is converted into a sequence of image tokens. For example, a single high-resolution image can generate hundreds or even thousands of image tokens, dramatically increasing the memory usage of the key-value (KV) cache.
Quantization and Memory Offloading Strategies
To run these models on typical consumer hardware (e.g., GPUs with 8 GB to 16 GB VRAM, or standard CPUs with 16 GB to 32 GB RAM), optimization is essential.
1. Hybrid Quantization (GGUF)
Quantization reduces the precision of model weights, typically from FP16 to 4-bit or 5-bit integers.
- Text Backbone Quantization: The text model can be heavily quantized (e.g., using
Q4_K_MorQ5_K_Mschemes) with minimal quality degradation. - Vision Encoder Sensitivity: The Vision Encoder is highly sensitive to quantization. Quantizing it below 8-bit precision often degrades visual comprehension, causing the model to miss small text or object details.
- Best Practice: Keep the Vision Projector and Encoder at FP16 or 8-bit precision, while quantizing the text backbone to 4-bit. Standard multimodal GGUF files packaged by the community follow this hybrid approach.
2. VRAM Budgeting & Layer Offloading
If your model exceeds your GPU’s VRAM capacity, you must split the execution between the GPU and CPU.
- The Vision Pass: The vision encoder pass runs once per image. Because it requires heavy parallel calculation, it should ideally run entirely in VRAM.
- Partial Layer Offloading: In tools like
llama.cpp, you can offload a specific number of layers to the GPU using the-nglflag. Ensure that the total VRAM usage (including the model weights, vision projector, and KV cache) does not exceed 90% of your GPU’s capacity to avoid memory allocation errors.
Serving Local VLMs: Ollama vs. llama.cpp
The two standard tools for running local vision models are Ollama and llama.cpp.
- Ollama: Best for rapid deployment and simple APIs. It automatically handles CUDA/Metal acceleration, schedules the vision encoder, and runs on both GPU and CPU.
- llama.cpp: Best for low-level performance tuning, custom quantization formats, and embedding directly into C++ applications.
Step-by-Step Implementation: Asynchronous VLM Microservice
Below is an asynchronous Python service using FastAPI and Ollama to process images locally. This microservice exposes a clean API to analyze local images, optimizing memory by using streaming payloads.
import os
import httpx
from fastapi import FastAPI, HTTPException, UploadFile, File, Form
from pydantic import BaseModel
from typing import Optional
# Initialize FastAPI app
app = FastAPI(
title="Local Multimodal Serving API",
description="Optimized local vision-language model serving wrapper.",
version="1.0.0"
)
# Ollama local endpoint configuration
OLLAMA_API_URL = os.getenv("OLLAMA_API_URL", "http://localhost:11434/api/generate")
VLM_MODEL_NAME = os.getenv("VLM_MODEL_NAME", "llama3.2-vision")
class VisionAnalysisResponse(BaseModel):
model: str
response: str
done: bool
@app.post("/api/v1/analyze", response_model=VisionAnalysisResponse)
async def analyze_image(
prompt: str = Form(..., description="The query instruction for the vision model"),
image: UploadFile = File(..., description="The image file to analyze")
):
"""
Exposes an API to upload an image file and analyze it locally
using the configured Vision-Language Model.
"""
# Validate file type
if not image.content_type.startswith("image/"):
raise HTTPException(status_code=400, detail="Uploaded file must be an image.")
try:
# Read the image content and encode it to Base64 string
image_bytes = await image.read()
import base64
image_b64 = base64.b64encode(image_bytes).decode("utf-8")
# Construct payload for Ollama
payload = {
"model": VLM_MODEL_NAME,
"prompt": prompt,
"images": [image_b64],
"stream": False,
"options": {
"temperature": 0.2, # Lower temperature for more factual analysis
"num_ctx": 4096 # Optimized context size for image tokens
}
}
# Send request to local Ollama instance
async with httpx.AsyncClient(timeout=120.0) as client:
response = await client.post(OLLAMA_API_URL, json=payload)
if response.status_code != 200:
raise HTTPException(
status_code=response.status_code,
detail=f"Local inference engine error: {response.text}"
)
data = response.json()
return VisionAnalysisResponse(
model=data.get("model", VLM_MODEL_NAME),
response=data.get("response", ""),
done=data.get("done", True)
)
except Exception as e:
raise HTTPException(status_code=500, detail=f"Internal Server Error: {str(e)}")
@app.get("/health")
async def health_check():
return {"status": "healthy", "configured_model": VLM_MODEL_NAME}
Crucial Local VLM Optimizations
When deploying local vision-language models, apply these structural configurations:
1. Optimize Context Size (num_ctx)
Each image processed consumes a significant portion of the context window (often 1,000 to 3,000 tokens depending on the patch size and resolution).
- If your context window is configured too low (e.g., 2048), the model will run out of space to generate text.
- Configure
num_ctxto at least 4096 or 8192 when running vision models.
2. Dynamic Image Resolution Scaling
Some VLMs (like Qwen2-VL or Llama 3.2 Vision) support native handling of high-resolution images by splitting them into tiles.
- For simple classification, OCR, or object detection, downscaling images to standard resolution (e.g., 448x448 or 672x672 pixels) before uploading them to the local server saves significant VRAM and processing time.
- This reduces the total sequence length and accelerates the prompt pre-fill phase.
3. Apple Silicon Unified Memory Tuning
For developers running on Mac Studio or MacBook Pro:
- Apple Silicon allows the GPU to share unified RAM with the CPU.
- To maximize model capacity, adjust the system-allocated memory limit for the GPU (Metal API limits VRAM allocations to roughly 70% of total memory by default). You can override this configuration to permit up to 85-90% usage for local models on dedicated developer machines.
Conclusion
Running vision-language models locally gives developers the ability to build advanced document parsing, security, and edge automation systems without sending sensitive data to external APIs. By combining hybrid quantization, careful VRAM layer allocation, and proper context window configuration, multimodal models can run efficiently on typical consumer hardware.
Get Weekly AI Architect Cost & Strategy Updates
Join 14,000+ developers receiving weekly, data-driven cost-reduction blueprints and production-ready agent guidelines.
