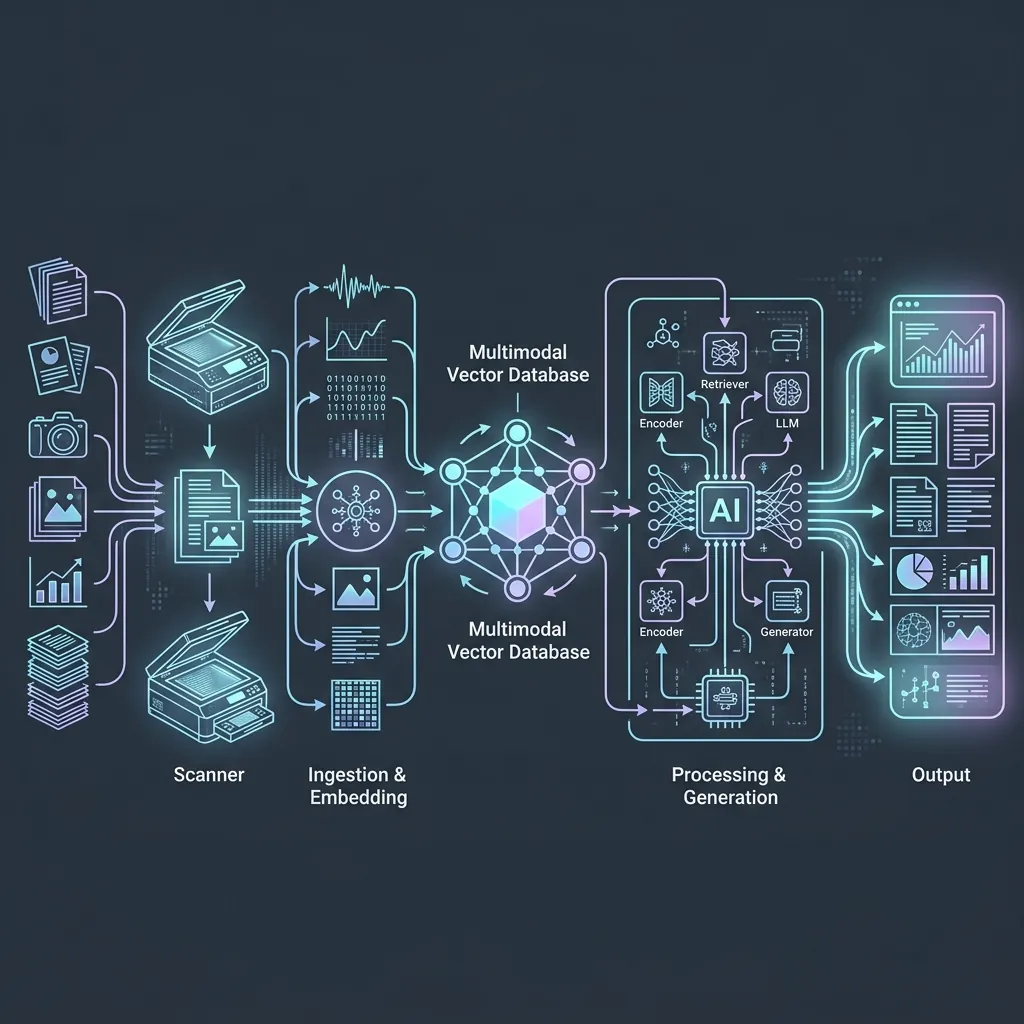
Retrieval-Augmented Generation (RAG) has established itself as the industry standard for reducing hallucinations and injecting private domain knowledge into large language models. However, traditional RAG architectures suffer from a critical limitation: they are fundamentally text-centric.
In the real world, the most valuable enterprise data is rarely locked in plain text. It exists in complex visual formats: medical imaging scans combined with patient history charts, financial earnings reports with nested tables and line charts, architectural blueprints, legal contracts with intricate signature pages, and insurance claims detailing physical property damage.
With the maturity of native vision-language models (VLMs) and multi-vector databases in 2026, Multimodal RAG has emerged as the frontier of enterprise AI. This article explores the architecture of Multimodal RAG and analyzes its high-impact applications in healthcare, fintech, insurtech, and legal systems.
The Architecture of Multimodal RAG
Traditional RAG relies on optical character recognition (OCR) or text extraction libraries to convert documents into plain text strings before chunking and embedding them. This process completely discards crucial layout information, relationships between text and graphics, and pure visual data.
Multimodal RAG solves this by using one of three standard architectural patterns:
1. The Visual Representation Pattern (Image-to-Vector)
Rather than extracting text, documents (like PDF pages or charts) are rendered directly into high-resolution images.
- A multimodal embedding model (e.g., Contrastive Language-Image Pre-Training, or CLIP-based models) converts each page image directly into a unified vector space.
- During retrieval, the user’s text query is embedded, and the vector database returns the highly similar images of the pages.
- These retrieved page images are passed directly into the VLM (e.g., Gemini 2.0 Pro or GPT-4o) for reasoning and answering.
2. The Structured Summary Pattern
- A VLM parses every document page, image, and chart during the ingestion phase, generating detailed structured text summaries of the visual components.
- These text summaries are chunked, embedded, and stored in a traditional vector database, while maintaining pointers to the original high-resolution raw images.
- When a user queries the database, the system retrieves the textual summaries, extracts the mapped raw image coordinates, and passes both the original images and the summaries to the VLM at query time.
3. The Multi-Vector Hybrid Pattern
- This pattern indexes text passages and visual components as separate vectors mapped to the same underlying document chunk.
- Text elements are parsed with dense embeddings, while charts and graphics are parsed using specialized visual encoders.
- A hybrid retrieval pipeline performs joint vector searches across both modalities, merging the results using Reciprocal Rank Fusion (RRF) before feeding the context into a native multimodal reasoning model.
High-Impact Industry Applications
1. Healthcare: Clinical Decision Support & Diagnostics
Clinical workflows are intensely visual. A patient’s diagnostic chart is a complex assembly of longitudinal blood lab reports, CT/MRI scan slices, pathology slide captures, and handwritten clinical intake notes.
Traditional text-only RAG misses crucial data in these environments:
- Medical Scan Triaging: By leveraging Multimodal RAG, an AI assistant can retrieve historical radiologist imaging reports alongside raw MRI scans to compare changes in tumor boundaries or bone density over time.
- Correlating Labs with Vitals: A clinical assistant can read patient monitor telemetry charts directly, correlating visual spikes in blood pressure with historical medication adjustment records to suggest diagnostic pathways.
- Interactive Chart Audits: Doctors can ask questions like “Are there any anomalies in the latest EKG chart compared to the patient’s baseline EKG from six months ago?” The system retrieves the visual assets, compares the waveforms, and flags anomalies.
2. Fintech: Layout-Aware Document Intelligence
Financial intelligence relies heavily on layout and spatial relationships. An earnings transcript, a balance sheet, or an SEC filing contains tables where the column headers, footnote indices, and graphical trends dictate the actual meaning of the numbers.
Multimodal RAG transforms how financial institutions analyze this data:
- Complex Table Parsing: Traditional text parsers scramble tables, separating row cells from column headers. Multimodal RAG bypasses this by allowing the VLM to read the visual table layout natively, retaining the exact structural context of numerical values.
- Graphical Trend Correlation: Financial analysts can query: “How does the capital expenditure trend represented in this company’s Q3 bar graph compare to their written cash flow assertions?” The system retrieves both the graphic and the corresponding text chapters, performing a visual-to-text validation audit.
- Cross-Document Financial Auditing: Automatically matching purchase invoice tables against shipping manifestation barcodes and payment ledger receipts to spot discrepancies in transaction chains.
3. Insurtech: Visual Claim Verification & Risk Analysis
Insurance claims processing relies heavily on physical evidence. Adjusters spend hours correlating damage photos with written policy guidelines, historical claims records, and repair estimates.
- Property & Auto Claims Triage: When a policyholder submits damage photos (e.g., a cracked car bumper or a hail-damaged roof), a Multimodal RAG system retrieves similar claims, visual repair catalogs, and the policyholder’s precise coverage contract.
- Automated Estimation Auditing: The system visually reviews the damage photo and compares it directly against the line items in the mechanic’s written invoice, ensuring that the estimated parts match the visible damage.
- Fraud Detection: By embedding and indexing historical accident photos, a vector database can flag if a submitted damage photo is identical or highly similar to a photo from a previous claim registered under a different name.
4. Legal: Visual Contract Auditing & Intellectual Property
Legal document repositories go beyond simple text sheets. Intellectual property audits, patent filings, and complex deeds contain schematic diagrams, visual trademark assets, and flowcharts governing corporate structures.
- Patent Infringement Discovery: Analysts can upload a design blueprint and query a patent database using Multimodal RAG. The system retrieves visually similar patent schematics, even if the written descriptions use completely different terminology.
- Flowchart-to-Text Reconciliation: Legal teams can audit complex corporate transaction flows by passing visual organization charts alongside written acquisition agreements to ensure compliance with ownership clauses.
- Signature & Seal Verification: Auditing multi-thousand-page mortgage portfolios to ensure that every visual signature box, notary seal, and date stamp is present and matches registered records.
Architectural Challenges & Mitigation Strategies
Implementing Multimodal RAG in enterprise environments introduces distinct engineering challenges:
1. High Prompt Token Overhead
Passing multiple high-resolution images to a VLM dramatically increases the context window usage. A single visual asset can consume thousands of tokens, impacting latency and API costs.
- Mitigation: Implement dynamic image cropping and resolution downscaling. Use models that natively support prompt caching (like Gemini 2.0+ or Claude 3.5 Sonnet) so that static visual pages don’t need to be reprocessed across multiple queries.
2. Vector Database Alignment
Mapping text descriptions and images into the same unified vector space requires advanced embedding models. If the vector alignment is off, a text query won’t successfully retrieve the corresponding visual assets.
- Mitigation: Use state-of-the-art dual-encoder models (e.g., modern CLIP derivatives or native multimodal embedding APIs) trained specifically on domain-specific data (such as financial charts or clinical schemas).
3. Layout Extraction Accuracy
Parsing multi-column documents or nested tables visually can still result in spatial reasoning mistakes by VLMs during extreme document lengths.
- Mitigation: Employ visual chunking strategies that segment pages into smaller, layout-coherent components (e.g., isolating a single table or chart alongside its immediate explanatory captions) before embedding and retrieval.
Conclusion
Multimodal RAG represents a massive leap forward in enterprise AI capability. By bridging the gap between textual instruction and visual reasoning, organizations can build assistants that truly understand the rich, unstructured format of real-world documents. Whether parsing complex clinical medical records, auditing financial earnings tables, verifying insurance claim photos, or indexing patent schematics, Multimodal RAG turns visual context into an actionable, competitive asset.
Get Weekly AI Architect Cost & Strategy Updates
Join 14,000+ developers receiving weekly, data-driven cost-reduction blueprints and production-ready agent guidelines.
