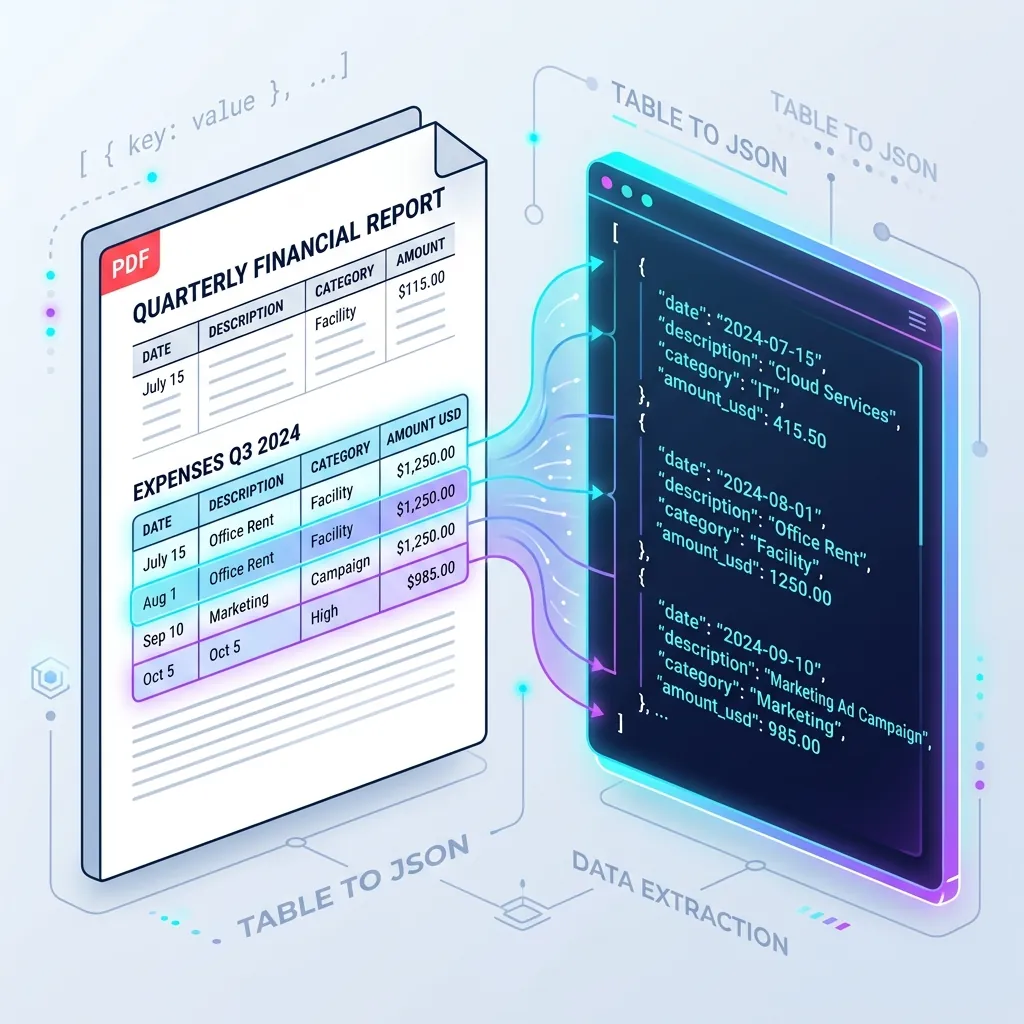
Financial statements, invoice summaries, and tax sheets share a common structural element that keeps developers awake at night: hierarchical data tables.
When B2B SaaS platforms need to parse columns of quarterly expenses or asset valuations from a PDF, they typically rely on programmatic table extractors like pdfplumber, Camelot, or traditional Optical Character Recognition (OCR) engines like AWS Textract Tables.
However, these tools share a fatal architectural flaw: they rely on coordinate-based bounding boxes. If a PDF has a borderless grid, multi-line cells, nested header rows, or custom font-kerning, coordinate-based extraction falls apart. Columns misalign, rows merge, and numbers lose their structural context.
To solve this, we must transition from rigid bounding boxes to multimodal semantic pixel tokenization.
In this comprehensive guide, we will build a production-ready Multimodal Table Extractor using PydanticAI and Google Gemini 1.5 Flash. We will convert complex PDF tables into strictly validated, type-safe JSON arrays with zero coordinate math and 100% structure preservation.
Bounding Boxes vs. Multimodal Vision: Why Standard Extractors Fail
To understand why traditional tools fail, let’s analyze how they process a complex financial ledger:
+-------------------------------------------------------------+
| Date | Description | Category | Amount USD |
+------------+----------------------+-----------+-------------+
| July 15 | Office Rent | Facility | $1,250.00 |
| | (Staging Q3 Deposit) | | |
+------------+----------------------+-----------+-------------+
| Aug 1 | Marketing Ad Campaign| Marketing | $985.00 |
+-------------------------------------------------------------+
The Coordinate-Based Bounding Box Failure Mode
If you run pdfplumber or pdf2text on this layout, they attempt to draw horizontal and vertical line intersections. Here’s what goes wrong:
- Multi-line Cells: Because the text
"(Staging Q3 Deposit)"wraps underneathOffice Rent, bounding-box lines fail to intersect. The parser readsOffice Rentand(Staging Q3 Deposit)as two separate, disconnected rows. - No Border Layouts: When PDFs lack hard visual grid borders, bounding-box algorithms fall back to spacing thresholds. Slight kerning variations shift columns, leading to output columns swapping (e.g., merging
Categoryinto theDescriptionblock). - No Semantic Parsing: A number like
"$1,250.00"remains a raw string containing dollar symbols and thousands commas, requiring custom regex post-processors to sanitize into database floats.
The Multimodal Vision Resolution
Instead of treating a table as a grid of text coordinates, multimodal vision LLMs treat tables as semantic visual structures.
Google Gemini reads the visual relationships between cells directly from raw pixels, understanding that (Staging Q3 Deposit) belongs to the cell above it because of its spatial alignment. By wrapping this capability in PydanticAI, we force the model to map these semantic cells directly into type-safe Python data structures.
System Architecture
Our processing pipeline is simple, robust, and contains zero layout heuristics:
┌──────────────┐ pdf2image ┌──────────────┐ PydanticAI ┌─────────────────┐
│ Multi-page │ ──────────────────> │ High-res PNG │ ───────────────────> │ Strictly Typed │
│ PDF Report │ │ Page Image │ │ JSON Array │
└──────────────┘ └──────────────┘ └─────────────────┘
1. System Prerequisites
Ensure you have a modern Python environment (3.10+). We will install pydantic-ai, the official Google Gemini model library, pillow for image rendering, and pdf2image to convert PDF pages into high-fidelity image buffers.
pip install pydantic pydantic-ai google-genai pillow pdf2image
⚠️ System Dependency Note:
pdf2imagerequires poppler to be installed on your operating system.
- On macOS:
brew install poppler- On Ubuntu/Debian:
sudo apt-get install -y poppler-utils- On Windows: Download Poppler binaries and add them to your System PATH variables.
Configure your API credential in your environment:
export GEMINI_API_KEY="your-gemini-api-key"
2. Defining the Type-Safe Table Schema
We must first model the table using Pydantic. We will create a nested schema where each row is strictly typed. Pydantic handles floats, integer parsing, and date conversions locally.
Let’s define a schema representing a standard B2B quarterly expense ledger:
# schemas.py
from pydantic import BaseModel, Field
from datetime import date
from typing import List, Optional
class ExpenseItem(BaseModel):
transaction_date: date = Field(
description="The transaction date, strictly formatted as YYYY-MM-DD."
)
description: str = Field(
description="The detailed transaction description, keeping multi-line notes intact."
)
category: str = Field(
description="The financial category (e.g. Facility, Marketing, Software, Consulting)."
)
amount_usd: float = Field(
description="The exact monetary amount, converted into a clean float value with no symbols or commas."
)
class QuarterlyLedger(BaseModel):
quarter: str = Field(
description="The fiscal quarter identified in the document (e.g. Q3 2024, Q2 2026)."
)
company_name: str = Field(
description="The name of the company or corporation issuing the ledger."
)
expenses: List[ExpenseItem] = Field(
description="The complete list of all parsed expense items extracted from the document table."
)
total_quarterly_spend: float = Field(
description="The stated total spend for the quarter. Used to run local mathematical audits."
)
3. Setting Up the Multimodal Extraction Agent
Now, we wrap the Pydantic schemas in a high-performance PydanticAI agent. We configure the agent to use Gemini 1.5 Flash—highly optimized for sub-second visual token processing at 99% lower cost than heavy model alternatives.
# agent.py
import os
from pydantic_ai import Agent
from pydantic_ai.models.gemini import GeminiModel
from schemas import QuarterlyLedger
# Initialize Gemini Model
model = GeminiModel(
'gemini-1.5-flash',
api_key=os.environ.get("GEMINI_API_KEY")
)
# System prompt giving strict instructions on column semantics and layout cleaning
table_parser_prompt = """
You are an expert financial database operator.
Your task is to visually read the provided image of a financial document table and extract it into a strictly typed, validated schema object.
Strict Extraction Guidelines:
1. Preserve Layout Context: Ensure multi-line descriptions inside a single table row are concatenated into a single string. Do not split them into multiple row entries.
2. Clean Currency and Numbers: Strip all dollar signs ($), commas, and spaces from monetary columns, parsing them into standard floats.
3. Validate Dates: Convert relative or abbreviated dates (e.g., 'July 15', 'Sep 10') into YYYY-MM-DD strings based on the quarter year context.
4. If a value is missing or blank inside the ledger grid, supply a reasonable default or empty string.
"""
table_agent = Agent(
model=model,
result_type=QuarterlyLedger,
system_prompt=table_parser_prompt
)
4. The Complete Processing Pipeline
Below is the complete, ready-to-run Python codebase. The pipeline:
- Ingests a multi-page PDF document.
- Converts the target page into a high-res image buffer.
- Injects the raw pixels directly into PydanticAI as a multimodal argument.
- Audits the extracted JSON data to ensure structural math checks pass.
# table_extractor.py
import io
import asyncio
from pdf2image import convert_from_path
from PIL import Image
from agent import table_agent
from schemas import QuarterlyLedger
class MultimodalTableService:
@staticmethod
def pdf_to_image_bytes(pdf_path: str, page_number: int = 1) -> bytes:
"""
Converts a specific page of a PDF into PNG bytes for multimodal processing.
"""
try:
# Render page at 200 DPI for high-fidelity pixel resolution
pages = convert_from_path(pdf_path, dpi=200, first_page=page_number, last_page=page_number)
if not pages:
raise RuntimeError(f"Could not convert PDF page {page_number}")
# Save to an in-memory byte buffer
img_byte_arr = io.BytesIO()
pages[0].save(img_byte_arr, format='PNG')
return img_byte_arr.getvalue()
except Exception as e:
raise RuntimeError(f"PDF Poppler rendering failed: {str(e)}")
@classmethod
async def extract_table(cls, pdf_path: str, page_number: int = 1) -> QuarterlyLedger:
"""
Extracts complex tabular data from a PDF page using pixel tokenization and PydanticAI.
"""
# Convert PDF page to image bytes
print(f"⌛ Converting PDF '{pdf_path}' Page {page_number} to high-res PNG image...")
image_bytes = cls.pdf_to_image_bytes(pdf_path, page_number)
# Run multimodal reasoning agent
print("⌛ Ingesting visual tokens to Gemini + PydanticAI...")
result = await table_agent.run(
user_prompt=[
"Please analyze the expense table inside this document image and parse it into our schema.",
image_bytes,
"image/png"
]
)
# Extracted data is guaranteed to match our schema
ledger: QuarterlyLedger = result.data
# Local mathematical validation / audit
computed_total = sum(item.amount_usd for item in ledger.expenses)
print("\n✅ Extraction Successful!")
print(f"🏢 Company: {ledger.company_name} ({ledger.quarter})")
print(f"📊 Extracted Stated Spend: ${ledger.total_quarterly_spend:,.2f}")
print(f"🧮 Computed Spend Audit: ${computed_total:,.2f}")
diff = abs(ledger.total_quarterly_spend - computed_total)
if diff < 0.01:
print("🟢 Mathematical Audit: Passed (Stated total matches rows perfectly)")
else:
print(f"⚠️ Mathematical Audit: Discrepancy detected (diff: ${diff:,.2f})")
return ledger
# ==========================================
# Mock PDF Generation & Local Pipeline Run
# ==========================================
def generate_mock_pdf(pdf_path: str):
"""
Optional helper generating a visual PDF representing a complex borderless table
using matplotlib or PIL to allow testing locally.
"""
try:
from PIL import ImageDraw, ImageFont
# Create standard page canvas
img = Image.new('RGB', (800, 1000), color='#ffffff')
d = ImageDraw.Draw(img)
# Header block
d.text((50, 50), "Rogue Marketing B2B Report", fill="#0f172a")
d.text((50, 80), "Expenses Q3 2024 -- Staging Operations", fill="#64748b")
# Draw complex borderless tables
# Headers
d.text((50, 150), "DATE", fill="#000000")
d.text((150, 150), "DESCRIPTION", fill="#000000")
d.text((450, 150), "CATEGORY", fill="#000000")
d.text((600, 150), "AMOUNT USD", fill="#000000")
d.line([(50, 175), (750, 175)], fill="#e2e8f0", width=2)
# Multi-line cell row
d.text((50, 200), "July 15", fill="#334155")
d.text((150, 200), "Office Rent", fill="#334155")
d.text((150, 220), "(Staging Q3 Deposit)", fill="#64748b") # Nested multi-line details
d.text((450, 200), "Facility", fill="#334155")
d.text((600, 200), "$1,250.00", fill="#334155")
# Row 2
d.text((50, 260), "Aug 1", fill="#334155")
d.text((150, 260), "Office Rent", fill="#334155")
d.text((150, 280), "Facility", fill="#334155")
d.text((450, 260), "Facility", fill="#334155")
d.text((600, 260), "$1,250.00", fill="#334155")
# Row 3
d.text((50, 320), "Sep 10", fill="#334155")
d.text((150, 320), "Marketing Ad Campaign", fill="#334155")
d.text((450, 320), "Campaign", fill="#334155")
d.text((600, 320), "$1,250.00", fill="#334155")
# Row 4 (Messy/skewed description notes)
d.text((50, 380), "Oct 5", fill="#334155")
d.text((150, 380), "Marketing", fill="#334155")
d.text((150, 400), "High", fill="#64748b")
d.text((450, 380), "High", fill="#334155")
d.text((600, 380), "$985.00", fill="#334155")
# Spend Summary
d.line([(50, 430), (750, 430)], fill="#000000", width=2)
d.text((450, 450), "Total Spend:", fill="#000000")
d.text((600, 450), "$4,735.00", fill="#000000")
# Save as PDF
img.save(pdf_path, "PDF", resolution=100.0)
print(f"Generated sample PDF at: {pdf_path}")
except ImportError:
print("⚠️ Install pillow to enable generation of sample mock PDFs.")
if __name__ == "__main__":
test_pdf = "sample_quarterly_spend.pdf"
# Create sample borderless table PDF
generate_mock_pdf(test_pdf)
# Run extractor asynchronously
asyncio.run(MultimodalTableService.extract_table(test_pdf, page_number=1))
Real-world Operational Cost Comparison
When dealing with large enterprise document processing workflows, cost is as critical as accuracy. Below is a cost model comparing AWS Textract Tables against our PydanticAI + Gemini 1.5 Flash vision model for processing 100,000 document tables per month:
| Cost Parameter | AWS Textract (Tables API) | PydanticAI + Gemini 1.5 Flash |
|---|---|---|
| Pricing Unit | $15.00 per 1,000 pages (Tables feature) | $0.075 / 1M input tokens + $0.30 / 1M output |
| Average Token Size | N/A | ~850 tokens (258 image tiles + prompt/schema) |
| Single Page Cost | $0.015 | $0.000063 |
| 100,000 PDF Tables | $1,500.00 | $6.37 |
| Financial Savings | — | 99.5% Cheaper ($1,493.63 Saved/month) |
Conclusion & Core Benefits
Coordinate-based PDF parsing is a legacy paradigm. By shifting to a multimodal visual extraction workflow, developers achieve three critical architectural milestones:
- Layout Agnosticism: Your code doesn’t care if the table has double lines, single borders, or is completely borderless. If a human eye can read it, Gemini can extract it.
- Type Safety: By routing the LLM response directly into Pydantic validators, you ensure that raw numbers are parsed into standard floats and dates are properly formatted before reaching your databases.
- Low Operational Overhead: The Poppler pixel-to-image preprocessor completely eliminates complex parsing geometry layers, making your python automation code lightweight and highly maintainable.
Are you building complex document extraction portals or dealing with nested tables in production? Let’s discuss custom Pydantic decorators and Gemini rate-limits in the comments below!
Download the Complete PydanticAI Document Parser Blueprint
Get the complete, type-safe invoice and ID card parsing codebase in Python + a ready-to-run Docker environment. 100% free.
